
CVPR2024
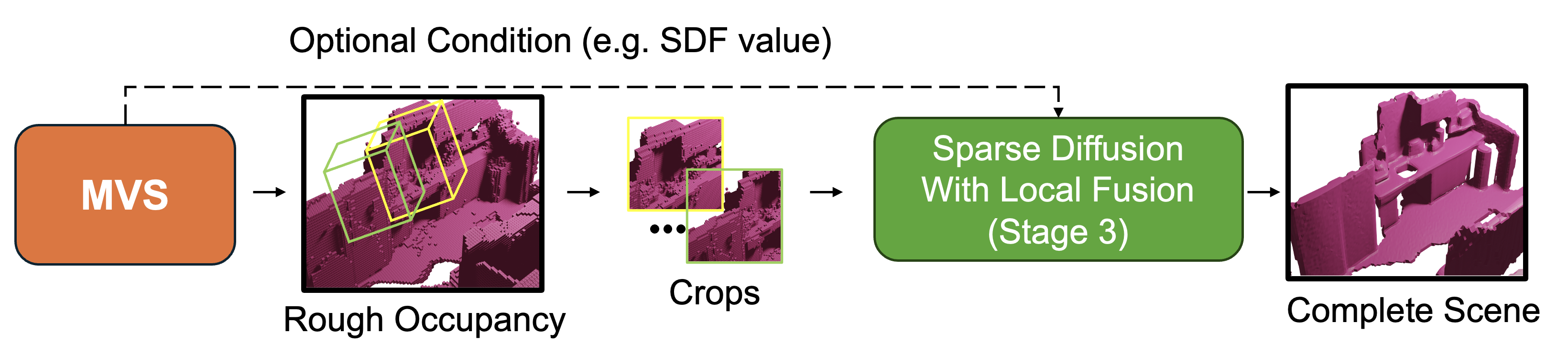
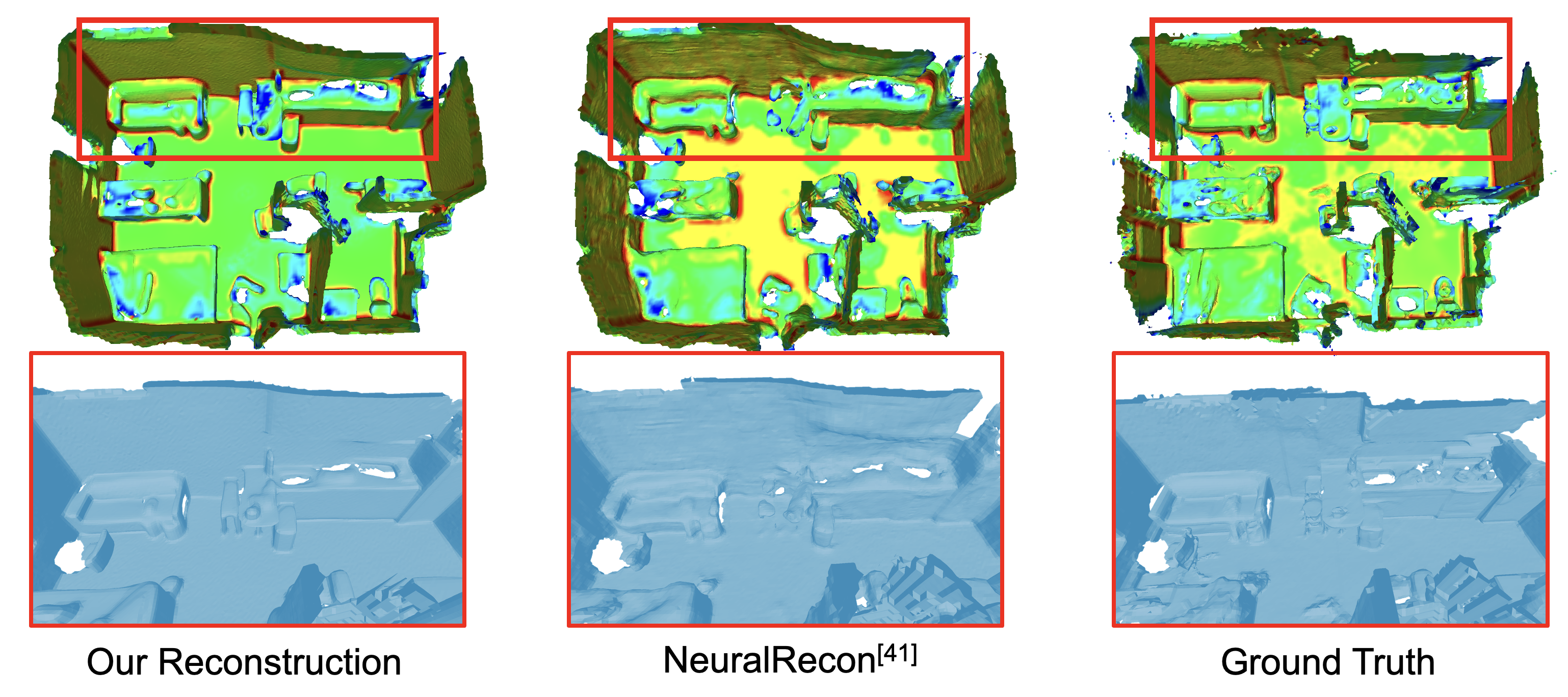
We present DiffInDScene, a novel framework for tackling the problem of high-quality 3D indoor scene generation, which is challenging due to the complexity and diversity of the indoor scene geometry. Although diffusion-based generative models have previously demonstrated impressive performance in image generation and object-level 3D generation, they have not yet been applied to room-level 3D generation due to their computationally intensive costs. In DiffInDScene, we propose a cascaded 3D diffusion pipeline that is efficient and possesses strong generative performance for Truncated Signed Distance Function (TSDF). The whole pipeline is designed to run on a sparse occupancy space in a coarse-to-fine fashion. Inspired by KinectFusion's incremental alignment and fusion of local TSDF volumes, we propose a diffusion-based SDF fusion approach that iteratively diffuses and fuses local TSDF volumes, facilitating the generation of an entire room environment. The generated results demonstrate that our work is capable to achieve high-quality room generation directly in three-dimensional space, starting from scratch. In addition to the scene generation, the final part of DiffInDScene can be used as a post-processing module to refine the 3D reconstruction results from multi-view stereo. According to the user study, the mesh quality generated by our DiffInDScene can even outperform the ground truth mesh provided by ScanNet.
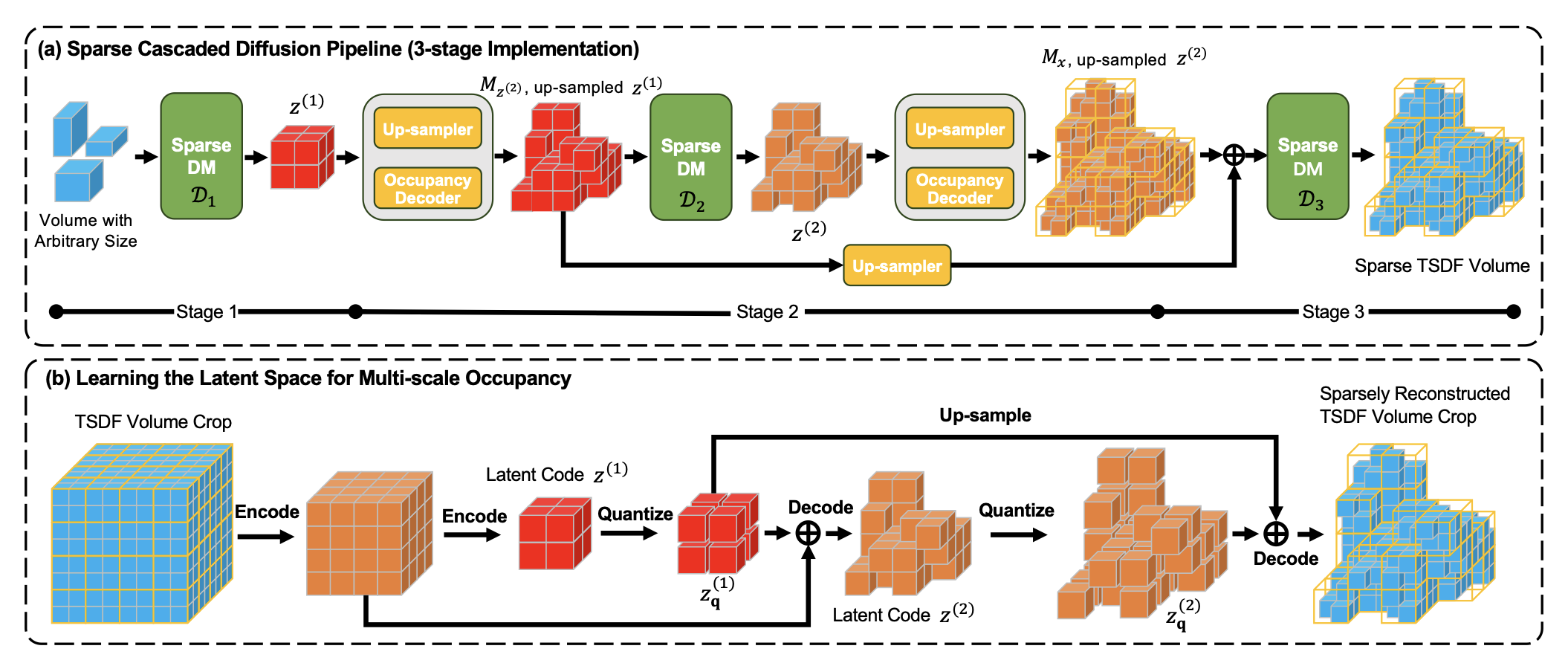
As shown in (a), we employ a cascaded diffusion model to generate the whole room in a coarse-to-fine manner. The first stage is to generate the coarse structure of the whole room. The following stages further refine the rough shape to a 3D occupancy field with higher resolutions. At the final stage, the resolution increases to the highest level, and we crop the whole scene to overlapped pieces to generate the final de- tailed Truncated Signed Distance Function (TSDF) volume. In every stage, we use a separate sparse diffusion model to reduce the resource consumption, which exclusively denoises on sparsely distributed occupancy.
To obtain hierarchical occupancy embeddings for latent diffusion in (a), we design a multi-scale Patch-VQGAN as (b), where latents with lower resolution can be decoded to the latent of higher resolution with sparse occupancy. Such latent representation enables the diffusion model to prune occupancy with increasing resolutions.

@inproceedings{ju2024diffindscene,
title={DiffInDScene: Diffusion-based High-Quality 3D Indoor Scene Generation},
author={Ju, Xiaoliang and Huang, Zhaoyang and Li, Yijin and Zhang, Guofeng and Qiao, Yu and Li, Hongsheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4526--4535},
year={2024}
}
}